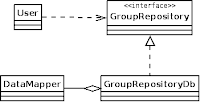
A Repository is a
Domain-Driven Design concept but it is also a standalone pattern. Repositories are an important part of the domain layer and deal with the encapsulation of objects persistence and reconstitution.
A common infrastructure problem of an object-oriented application is how to deal with persistence and retrieval of objects. The most common way to obtain references to entities (for example, instances of the User, Group and Post class of a domain) is through navigation from another entity. However, there must be a root object which we call methods on to obtain the entities to work with. Manual access to the database tables violates every law of good design.
A Repository implementation provides the illusion of having an
in-memory collection available, where all the objects of a certain class are kept. Actually, the Repository implementation has dependencies on a database or filesystem where thousands of entities are saved as it would be impractical to maintain all the data in the main memory of the machine which runs the application.
These dependencies are commonly wired and injected during the construction process by a
factory or a
dependency injection framework, and domain classes are only aware of the interface of the Repository. This interface logically resides in the domain layer and has no external dependencies.
Let's show an example. Suppose your User class needs a choiceGroups() that lists the groups which an instance of User can subscribe to. There are business rules which prescribe to build a criteria with internal data of the User class, such as the role field, which can assume the values 'guest', 'normal' or 'admin'.
This method should reside on the User class. However, to preserve
a decoupled and testable design, we cannot access the database directly to retrieve the Group objects we need from the User class, otherwise we would have a dependency, maybe injected, from the User class which is part of the domain layer to a infrastructure class. This is want we want to avoid as we want to run thousands of fast unit tests on our domain classes without having to start a database daemon.
So the first step is to encapsulate the access to the database. This job is already done in part from the
DataMapper implementation: [N]
Hibernate,
Doctrine2, Zend_Entity. But using a DataMapper in the User class let its code do million of different things and call every method on the DataMapper facade: we want to
segregate only the necessary operations in the contract between the User class and the bridge with the infrastructure, as methods of a Repository interface.
A small interface is simply to mock out in unit tests, while a DataMapper implementation usually can only be substituted by an instance of itself which uses a lighter database management system, such as
sqlite.
So we prepare a GroupRepository interface:
<?php
interface GroupRepository
{
public function find($id);
/**
* @param $values pairs of field names and values
* @return array (unfortunately we have not Collection in php)
*/
public function findByCriteria($values);
}Note that a Repository interface is
pure domain and we can't rely on a library or framework for it. It is in the same domain layer of our User and Group classes.
The User class now has dependencies only towards the domain layer, and it is rich in functionality and
not anemic as we do not have to break the encapsulation of the role field and the method is cohesive with the class:
class User
{
private $_role;
// ... other methods
public function choicesGroups(GroupRepository $repo)
{
return $repo->findByCriteria(array('roleAllowed', $this->_role));
}
}Now we should write an actual implementation of GroupRepository, which will bridge the domain with the production database.
class GroupRepositoryDb implements GroupRepository
{
/**
* It can also be an instance of Doctrine\EntityManager
*/
public function __construct(Zend_Entity_Manager_Interface $mapper)
{
// saving collaborators in private fields...
}
// methods implementations...
}In testing, we pass to the choicesGroups() method a mock or a fake implementation which is
really an in-memory collection, and which can have also utility methods for setting up fixtures. Unit testing involves a few objects and keeping them all in memory is the simplest solution. Moreover, we have
inverted the dependency as now both GroupRepositoryDb and User depend on an abstraction instead of on an implementation.
Another advantage of the Repository and its segregated interface is the reuse of queries. The
User class has no knowledge of any SQL/DQL/HQL/JPQL language, which is highly dependent on the internal structure of the Group class and its relations. What is established in the contract (the GroupRepository interface) are only logic operations which take domain data as parameters.
For instance, if Group changes to incorporate a one-to-many relation to the Image class, the loading code is not scattered troughout the classes which refer to Group, like User, but is centralized in the Repository. If you do not incorporate a generic DataMapper, the Repository becomes a
Data Access Object; the benefit of isolating a Repository implementation via a DataMapper is
you can unit test it against a lightweight database. What you are testing are queries and results, the
only responsibility of a Repository.
Note that in this approach
the only tests that need a database are the ones which instantiate a real Repository and are focused on it, and not your entire suite. That's why the DDD approach is best suited for complex applications which require tons of automatic testing. Fake repositories should be used in other unit tests to prevent them from becoming integration tests.
Also the old
php applications which once upon a time only created and modified a list of entities are growing in size and complexity, incorporating validation and business rules. Generic DataMappers
a la Hibernate are becoming a reality also in the php world, and they can help the average developer to avoid writing boring data access classes.
Though, their power should be correctly decoupled from your domain classes
if your core domain is complex and you want to isolate it. Repositories are a way to accomplish this decoupling.



















